[Guide] In order to better understand the operation of neural networks, today I will only explain the mathematical principles behind neural networks for everyone. The author’s purpose of writing this article is to organize the knowledge he has learned; the second purpose is to share it with everyone. If there is puzzled knowledge while studying, I hope this article can help everyone’s learning and learning. understanding. For those with a weak foundation in algebra and calculus related content, although the article involves a lot of mathematical knowledge, I will try to make the content easy for everyone to understand.
â–ŒAnalyze the mathematics behind the deep network
Nowadays, there are many high-level specialized libraries and frameworks such as Keras, TensorFlow, PyTorch, so we don’t have to worry about the weight of the matrix too much, or the storage and calculation scale when deriving the activation function used is too large. Up. Based on these frameworks, when we build a neural network, even a network with a very complex structure, only a small amount of input and code is enough, which greatly improves the efficiency. In any case, the principles and methods behind neural networks are of great help to tasks such as architecture selection, hyperparameter tuning, or optimization.
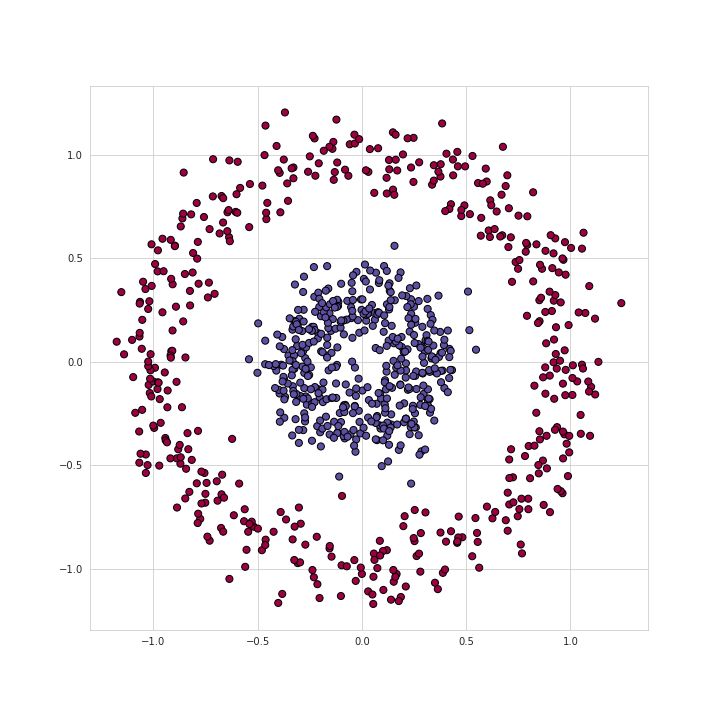
Figure 1 Visualization of the training set
For example, we will use the training set data shown in the figure above to solve a binary classification problem. As can be seen from the above figure, the data points form two circles, which is not easy for many traditional machine learning algorithms, but now a small neural network may solve this problem well. To solve this problem, we will build a neural network: including five fully connected layers, each layer contains a different number of units, the structure is as follows:
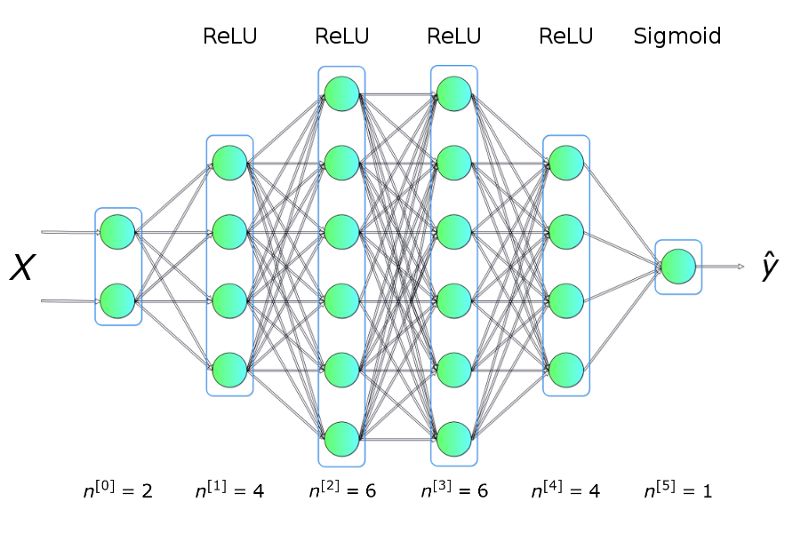
Figure 2 Neural network architecture
Among them, the hidden layer uses ReLU as the activation function, and the output layer uses Sigmoid. This is a very simple architecture, but it is enough to solve and explain the problem.
Solve with KERAS
First of all, I will introduce a solution to everyone, using one of the most popular machine learning libraries-KERAS.
fromkeras.modelsimportSequentialfromkeras.layersimportDensemodel=Sequential()model.add(Dense(4,input_dim=2,activation='relu'))model.add(Dense(6,activation='relu'))model.add(Dense(6 ,activation='relu'))model.add(Dense(4,activation='relu'))model.add(Dense(1,activation='sigmoid'))model.compile(loss='binary_crossentropy',optimizer= 'adam',metrics=['accuracy'])model.fit(X_train,y_train,epochs=50,verbose=0)
As I mentioned in the introduction, a small amount of input data and code is enough to build and train a model, and the classification accuracy on the test set is almost 100%. In a nutshell, our task is actually to provide hyperparameters (number of layers, number of neurons in each layer, activation function, or number of iterations) consistent with the selected architecture. Let me show you a super cool visualization result, which I got during the training process:
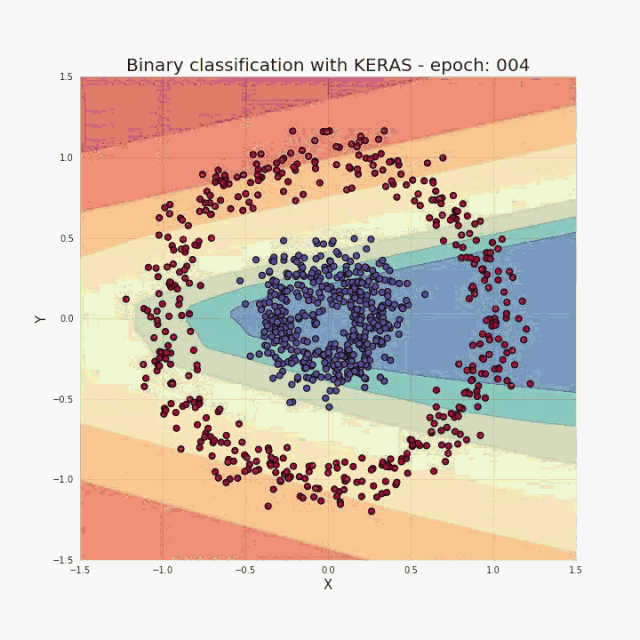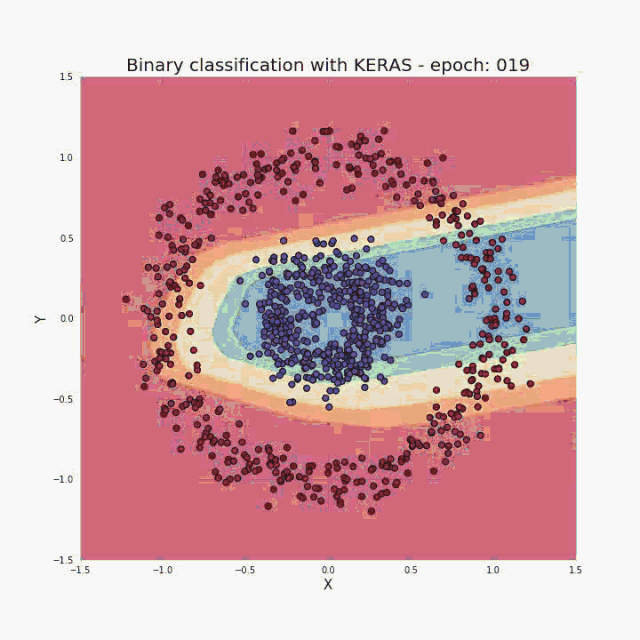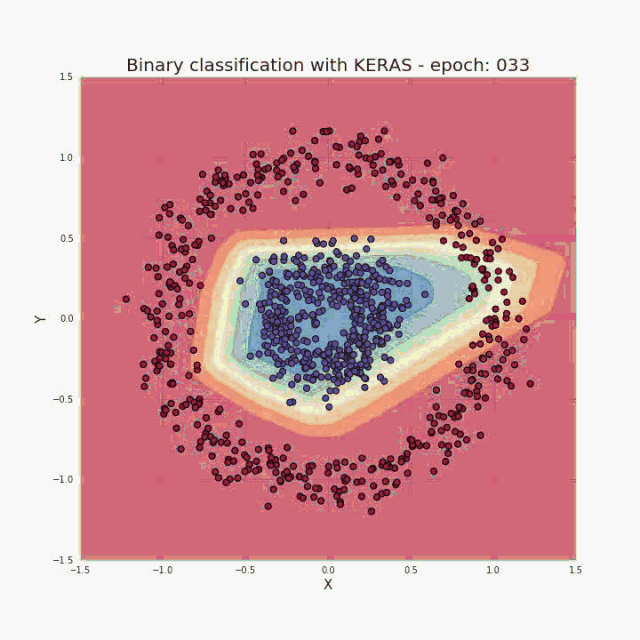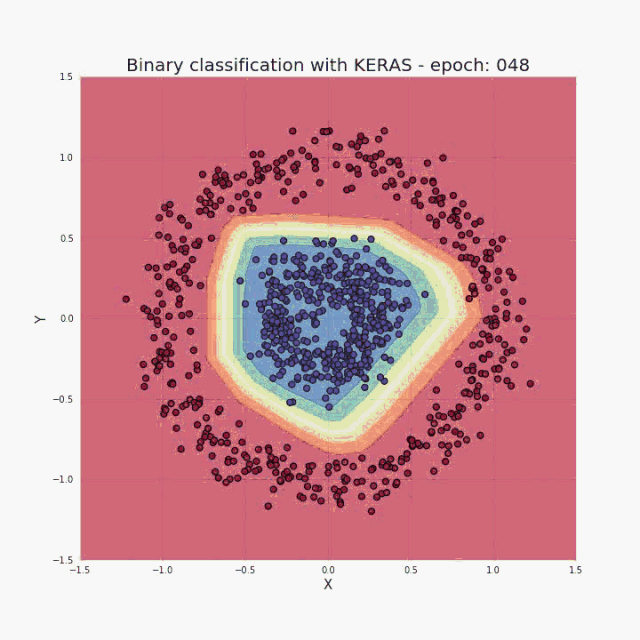
Figure 3 Visualization of the correct classification area in training
Now let's analyze the principle behind this.
â–ŒWhat is a neural network?
Let's start with the key question: What is a neural network? It is a biologically inspired method for constructing computer programs that can learn and independently interpret the connections in data. As shown in Figure 2 above, the network is a collection of neurons in each layer. These neurons are arranged in columns and connected to each other for communication.
â–ŒSingle neuron
Each neuron takes the value of a set of x variables (from 1 to n) as input, and calculates the predicted y-hat value. Assuming that there are m samples in the training set, the vector x represents the value of each feature of one of the samples. In addition, each unit has its own parameter set to learn, including weight vector and bias, which are represented by w and b, respectively. In each iteration, the neuron calculates the weighted average of the vector x based on the weight vector of the current round, plus the deviation. Finally, the calculation result is substituted into a nonlinear activation function g. I will introduce some of the most popular activation functions below.
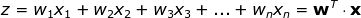

Figure 4 Single neuron
â–ŒSingle layer
Now let's look at how the overall layer in the neural network is calculated. We will integrate the calculations in each unit, perform vectorization, and then write it in the form of a matrix. In order to unify the symbols, we choose the l-th layer to write the matrix equation, and the subscript i represents the i-th neuron.

Figure 5 Single-layer neural network
One thing to note: When we write equations for a single unit, x and y-hat are used, which represent the feature column vector and predicted value, respectively. But when we write to the entire layer, we need to use the vector a to represent the activation value of the corresponding layer. Therefore, the vector x can be regarded as the activation value of the 0th input layer. Each neuron in each layer similarly satisfies the following equation:
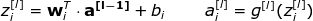
For clarity, here are all the expressions for the second level:
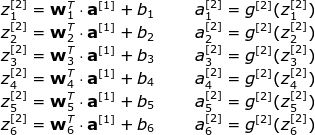
It can be seen that the expressions of each layer are similar. It is very inefficient to use a for loop, so in order to speed up the calculation, we use vectorization. First, stack the transposition of the weight vector w into a matrix W. Similarly, the deviations of each neuron are also piled together to form a column vector b. From this, we can easily write a matrix equation to represent the calculation of all neurons in a certain layer. The dimensions of the matrices and vectors used are expressed as follows:

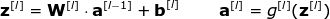

â–ŒMulti-sample vectorization
The equations we have written so far contain only one sample. However, in the learning process of neural networks, a huge data set is usually processed, up to millions of inputs. Therefore, the next step requires multi-sample vectorization. We assume that the data set contains m inputs, and each input has nx features. First, stack the column vectors x, a, z of each layer into matrices X, A, Z, respectively. Then, rewrite the previous equation based on the new matrix.


â–ŒWhat is an activation function? Why do we need it?
The activation function is one of the key elements of neural networks. Without them, the neural network is just a combination of some linear functions, and it can only be a linear function itself. Our model has a complexity limit and cannot exceed logistic regression. Among them, the non-linear element ensures better adaptability and can provide some complex functions in the learning process. The activation function also has a significant impact on the speed of learning, which is also one of the criteria when choosing. Figure 6 shows some commonly used activation functions. In recent years, the most widely used activation function in the hidden layer is probably ReLU. However, when we are doing binary classification problems, we sometimes still use sigmoid, especially in the output layer, we want the value returned by the model to be between 0 and 1.

Figure 6 Common activation function and its derivative function image
â–ŒLoss function
The basic source of information about the progress of the learning process is the value of the loss function. Generally speaking, the loss function can indicate how far we are from the "ideal" value. In this example, we use binary crossentropy as the loss function, but there are other loss functions that require specific analysis of specific issues. The two-element cross entropy function is expressed as follows:
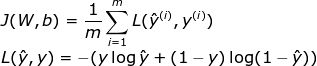
The following figure shows the change of its value during the training process. It can be seen how its value increases and decreases with the number of iterations, and how the accuracy improves
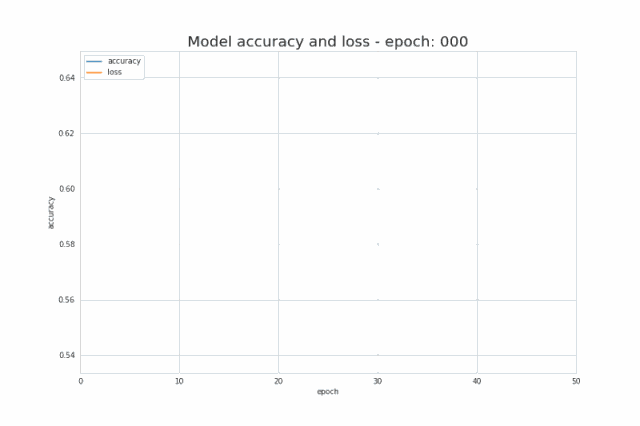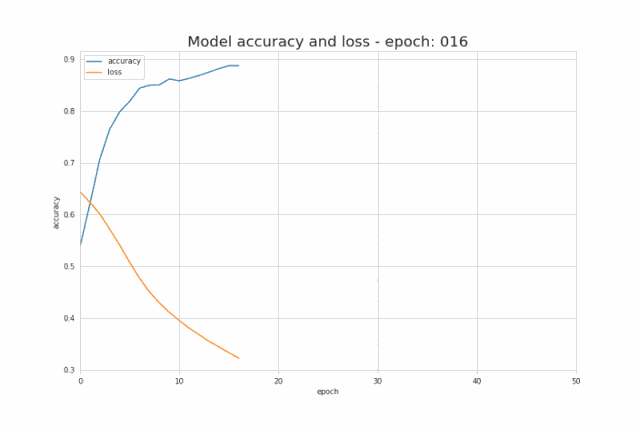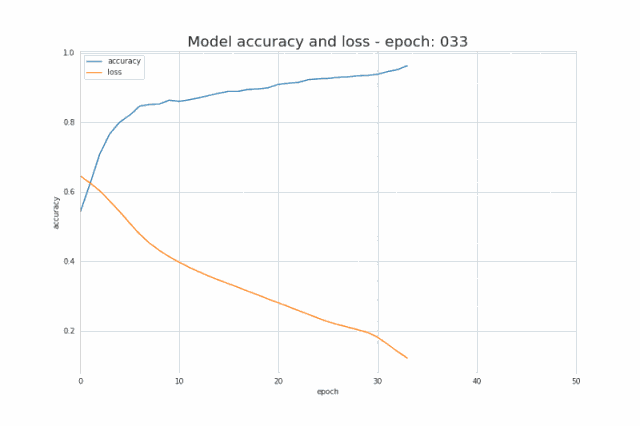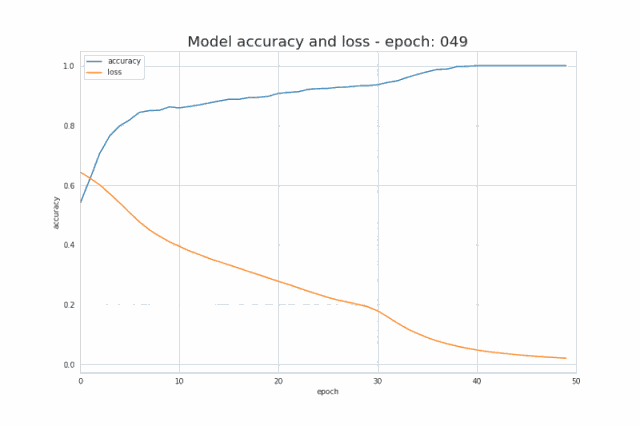
Figure 7 Changes in accuracy and loss during training
â–ŒHow do neural networks learn?
The learning process is actually constantly updating the values ​​of parameters W and b to minimize the loss function. To this end, we use calculus and gradient descent methods to find the minimum of the function. In each iteration, we will calculate the partial derivative value of the loss function with respect to each parameter in the neural network. For those who are not familiar with this aspect of calculation, let me briefly explain that the derivative can describe the (slope) of a function. We already know how the iterative variables will change. In order to have a more intuitive understanding of gradient descent, I showed a visual animation, from which we can see how we approach the minimum through successive iterations step by step. . The same is true in neural networks-the gradient calculated in each iteration shows the direction in which we should move. The main difference between them is that the neural network needs to calculate more parameters. To be precise, how to calculate such a complex derivative?
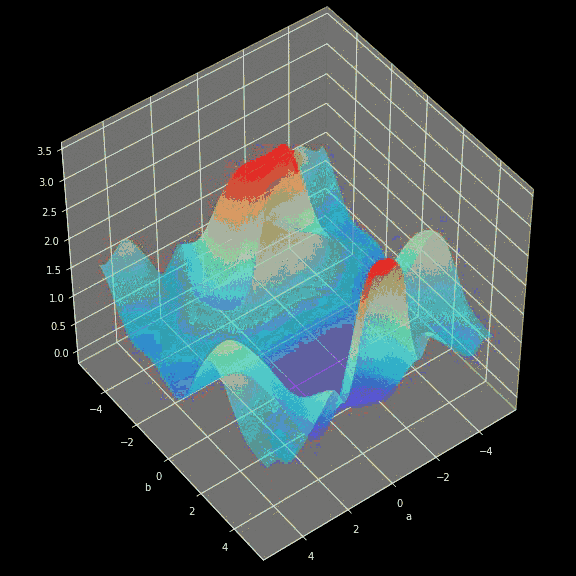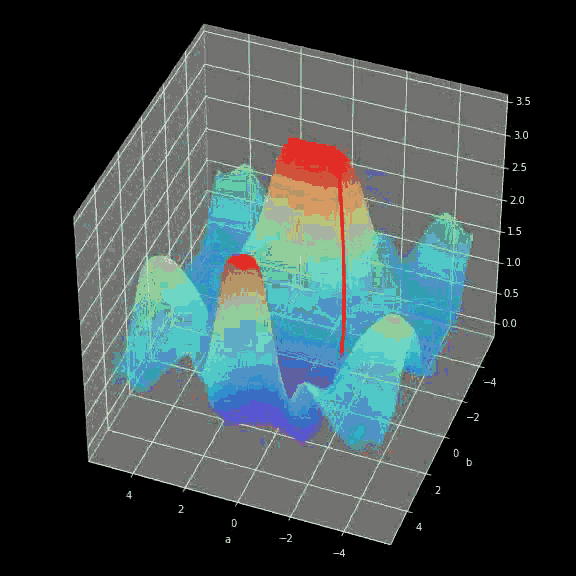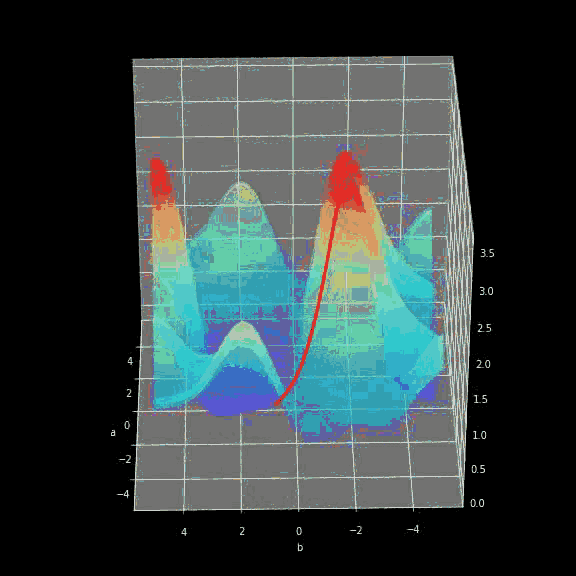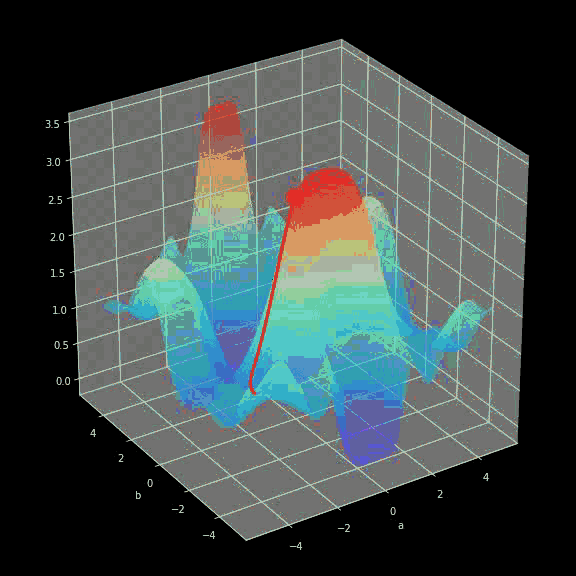
Figure 8 Dynamic gradient descent
â–ŒBack propagation algorithm
Backpropagation algorithm is an algorithm that can calculate very complex gradients. In the neural network, the adjustment formula of each parameter is as follows:
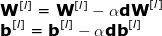
Among them, the hyperparameter α represents the learning rate, which is used to control the update step size. The selected learning rate is very important-too small, NN learns too slowly; too large to reach the minimum. Use the chain rule to calculate dW and db-the partial derivative of the loss function with respect to W and b. The dimensions of dW and db are equal to those of W and b. Figure 9 shows a series of derivative operations in the neural network, from which we can clearly see how the forward and backward propagation jointly optimize the loss function.
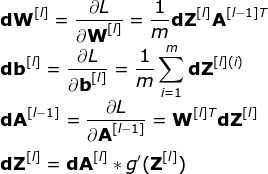

Figure 9 Forward and backward propagation
â–ŒConclusion
I hope this article will help you understand the mathematical principles used in neural networks. When we use neural networks, it is helpful to understand the basic principles of this process. Although the content described in the article is only the tip of the iceberg, they are all the most important knowledge points in my opinion. Therefore, I strongly recommend that everyone try to program a small neural network independently, don't rely on the framework, just try it with Numpy.
Soft Starter,Ac Motor Soft Starter,Soft Starter For Machinery,3-Phase Soft Starter
Zhejiang Kaimin Electric Co., Ltd. , https://www.ckmineinverter.com