FPGA (Field-Programmable Gate Array), field programmable gate array, which is the product of further development based on PAL, GAL, CPLD and other programmable devices. It appears as a kind of semi-custom circuit in the application-specific integrated circuit (ASIC) field, which not only solves the defect of the custom circuit, but also overcomes the shortcomings of the original programmable device with a limited number of gates.
FPGA adopts the concept of logical cell array LCA (Logic Cell Array), including three parts of configurable logic module CLB (Configurable Logic Block), input output module (IOB) and internal connection (Interconnect). Field programmable gate arrays (FPGAs) are programmable devices that have a different structure than traditional logic circuits and gate arrays (such as PAL, GAL, and CPLD devices). The FPGA uses a small lookup table (16×1 RAM) to implement the combinatorial logic. Each lookup table is connected to the input of a D flip-flop. The flip-flop drives other logic circuits or drives the I/O. This makes it possible to implement a combination. Logical functions can also implement basic logic unit modules for sequential logic functions. These modules are connected to each other or to I/O modules using metal wires. FPGA logic is implemented by loading programming data into internal static memory cells. Values ​​stored in memory cells determine the logic functions of logic cells and the connection between modules or modules and I/O, and ultimately determine the FPGA can realize the function, FPGA allows infinite programming.

Both the CPU and the GPU belong to the von Neumann structure, instruction decode execution, shared memory. The reason why FPGAs are faster than CPUs and GPUs is essentially due to their architecture without instructions and without shared memory.
In the Feng's architecture, since the execution unit may execute arbitrary instructions, it needs an instruction memory, a decoder, various instruction operators, and branch jump processing logic. The function of each logic cell of the FPGA is already determined during reprogramming and no instructions are required. The use of memory in the Feng structure has two functions: 1 Save state. 2 Communication between execution units.
1) Save state: The registers and on-chip memory (BRAM) in the FPGA are part of their own control logic and do not require unnecessary arbitration or caching.
2) Communication requirements: The connection between each logical unit of the FPGA and the surrounding logical units is already determined at the time of reprogramming and does not require communication through shared memory.
In computationally intensive tasks:
In data centers, the core advantage of FPGAs over GPUs is latency. Why is the FPGA less latency than GPU? Essentially the difference in architecture. FPGAs have both pipeline parallelism and data parallelism, while GPUs have almost only data parallelism (pipeline depth limited).
There are 10 steps to process a data packet. The FPGA can build a 10-stage pipeline. Different stages of the pipeline process different data packets. Each data packet flows through 10 levels and is processed. Each processed packet can be output immediately. The GPU data parallel method is to do 10 calculation units, each computing unit is also dealing with different data packets, but all computing units must follow the same pace, do the same thing (SIMD). This requires that 10 packets must be entered together. Pipeline parallelism achieves lower latency than data parallelism when the tasks are arriving on a one-by-one basis rather than in batches. Therefore, for pipelined computing tasks, FPGAs inherently have a latency advantage over GPUs.
ASICs are the best in terms of throughput, latency, and power consumption. However, its R&D cost is high and its cycle is long. FPGA flexibility protects assets. Data centers are leased to different tenants for use. Some machines have a neural network accelerator card, some have a bing search accelerator card, and some have a network virtual accelerator card, scheduling and operation of the task will be very troublesome. Using FPGAs can maintain the homogeneity of the data center.
In communication-intensive tasks, FPGAs have more advantages than GPUs and CPUs.
1 Throughput: The FPGA can be directly connected to a 40Gbps or 100Gbps network cable to process data packets of any size at wire speed. However, the CPU needs a network card to receive data packets. The GPU can also process data packets with high performance, but the GPU has no network port. , Also need network card, so throughput is limited by the network card and (or) CPU.
2 Delay: The network card transmits the data to the CPU. After the CPU processes the data, it is transmitted to the network card. In addition, the clock interruption and task scheduling in the system increase the delay instability.
In summary, the main advantages of FPGAs in data centers are stable and extremely low latency, which is suitable for streaming compute-intensive tasks and communication-intensive tasks.
The biggest difference between FPGAs and GPUs lies in the architecture. FPGAs are more suitable for streaming processing that requires low latency, and GPUs are more suitable for processing large volumes of isomorphic data.
Winning or losing does not matter. The lack of instructions is at the same time the strengths and weaknesses of FPGAs. Each time you do something different, you must use a certain amount of FPGA logic resources. If the tasks to be done are complex and non-reproducible, they will consume a large amount of logical resources, most of which are idle. At this time, it is better to use a von Neumann structured processor.
The FPGA and the CPU work together, with a strong locality and repeatability attributed to the FPGA, and a complex CPU.
Difference between CPU and GPUThe reason why PUs and GPUs differ greatly is due to their different design goals. They address two different application scenarios. The CPU needs to be very versatile to deal with a variety of different data types. At the same time, the logic judgment will introduce a large number of branch jumps and interrupt handling. All of these make the internal structure of the CPU extremely complicated. The GPU is faced with highly-typed, non-dependent, large-scale data and a clean computing environment that does not need to be interrupted.
So CPU and GPU show a very different architecture (schematic diagram):
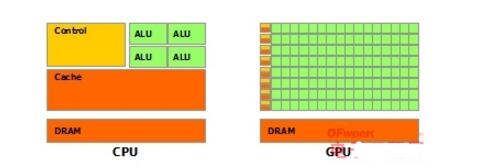
The picture is from the nVidiaCUDA document. The green one is the calculation unit, the orange-red one is the storage unit, and the orange one is the control unit.
The GPU employs a large number of computing units and a very long pipeline, but only a very simple control logic and saves the Cache. The CPU is not only occupied by a large amount of space by the Cache, but also has complex control logic and many optimization circuits. In comparison, the computing power is only a small part of the CPU.
So unlike a CPU that excels in logic control and general-purpose type data operations, GPUs are good at large-scale concurrent computations, which is exactly what password cracking and so forth need. Therefore, in addition to image processing, the GPU is also increasingly involved in calculations.
2. A long time ago, probably around 2000, the graphics card was also called a graphics accelerator card. What is generally called an accelerator card is not a core component, and is similar to the M7 coprocessor used by Apple. This kind of thing is better, neither is nor is it not, as long as there is a basic graphic output you can access the monitor. Until then, only a few high-end workstations and home consoles could see such a separate graphics processor. Later, with the popularity of PCs, the development of games and market hegemony such as Windows appeared, simplifying the workload of graphics hardware manufacturers. Graphics processors, or graphics cards, gradually became popular.
To understand the difference between GPU and CPU, you need to understand what the GPU is designed to do. Modern GPU functionality covers all aspects of graphic display. We only take one of the simplest directions as an example.
Everyone may have seen the above picture, this is a test of the old version of DirectX, is a rotating cube. Showing a cube like this takes a lot of steps. Let's think about it first. Imagine he is a wireframe with no side "X" image. Simplify it a little, there is no connection, it is eight points (the cube has eight vertices). Then the question is simplified into how to make these eight points turn. First of all, when you create this cube, you must have the coordinates of the eight vertices. The coordinates are represented by vectors, and therefore at least a three-dimensional vector. Then "rotate" this transformation, which is represented by a matrix in linear algebra. Vector rotation is to multiply this matrix by vector. To turn these eight points is to multiply the vector and matrix eight times. This kind of calculation is not complicated. It is nothing more than a few product additions, which means that the calculation is relatively large. Eight points will count eight times, and 2000 points will count 2,000 times. This is part of the GPU work, vertex transformations, and this is the simplest part. There are still a lot of more trouble than that.
Most of the GPU's work is like this. It is computationally intensive, but it has no technical content and it is repeated many times. Just as if you have a job that needs to count hundreds of millions of times less than one hundred, plus, minus, multiply and divide, the best way is to hire dozens of elementary school students to count together, and one person to count them. In any case, these calculations have no technical content and are purely physical. The CPU is like an old professor. The integral differential will be calculated. It means that the salary is high. An old professor is a top 20 primary school students. If you were Foxconn, which one would you hire? The GPU is like this, using many simple computing units to complete a large number of computing tasks, pure human-sea tactics. This strategy is based on the premise that the work of Pupil A and Pupil B is not dependent on each other and is independent of each other. Many problems involving large numbers of calculations have such characteristics, such as cracking passwords, mining, and many graphics calculations. These calculations can be broken down into multiple identical simple tasks, each of which can be assigned to a primary school student. But there are still some tasks that involve "flow" issues. For example, when you go to a blind date, both parties look pleasing to continue to develop. There is no way you haven't met yet. There's someone who's got the cards. This more complicated issue is done by the CPU.
All in all, the CPU and GPU are different because of the tasks they were originally used to handle, so there is a big difference in design. Some tasks are similar to the ones that the GPU was originally used to solve, so use the GPU to calculate it. The speed of the GPU's computing depends on how many elementary school students are employed. The CPU's speed of operation depends on how powerful the professor has been. Professor's ability to handle complex tasks is to squash primary school students, but for less complex tasks, it still can not withstand more people. Of course, the current GPU can also do some more complicated work, which is equivalent to upgrading to junior high school students. But also need the CPU to feed the data to the mouth in order to start working, it still depends on the CPU to control.
Install on Auto/Aircraft, Auto Signal, Recreation Vehicles, Trucks/ Trailers, Marine/ Boats,Motorbikes etc.
Be used as Direction light, emergency vehicle lamp, dashboard light, Dash light, instrument light, indicator light, stop lamp, brake light, tail Lamp, side lamp, parking lamp, tag lamp, license plate light, turn signal lamp, dome lights, interior lighting, warning indicator, etc.
Yacenter has experienced QC to check the products in each process, from developing samples to bulk, to make sure the best quality of goods. Timely communication with customers is so important during our cooperation.
If you can't find the exact product you need in the pictures,please don't go away.Just contact me freely or send your sample and drawing to us.We will reply you as soon as possible.
Brake Light Wiring,Brake Light Wiring Harness,Brake Light Harness,Christmas Light Wire Harness
Dongguan YAC Electric Co,. LTD. , https://www.yacentercns.com