[Guide] The natural language dialogue system is covering more and more life and service scenarios. At the same time, the understanding of natural language dialogue and the dialogue recall rate of fine knowledge are still technically challenging.
Heuristic dialogue enables the dialogue system to actively discover relevant knowledge through the establishment of topic associations between knowledge points, give full play to the synergy of knowledge, guide the dialogue process, and actively deliver knowledge to users at the right time. Knowledge is not only passively searched in the form of knowledge graphs or Q&A libraries. Knowledge in heuristic dialogue combines prior experience and user dialogue habits, thereby possessing knowledge roles, making dialogue understanding and dialogue flow more natural and more valuable to users .
In this public course, the AI ​​Technology Base Camp invited Ge Fujiang, the head of the NLP department of Spitz, to give a systematic explanation and sorting out on "Knowledge Management in Heuristic Dialogues".
The following content is organized for the base camp open class.
Today I will share with you, about the knowledge management system in heuristic dialogue, the content to be shared includes the following five aspects:

â–ŒThe architecture of the dialogue system
The first is the architecture of the dialogue system. Let's take a look at the process of the dialogue system.

In general conversation system application scenarios, such as smart speakers, smart TVs, and current vehicle-mounted devices, when the user says a question, the smart customer service will automatically ask questions and dialogue. The basic process of such a system is that it receives the user A question or a sentence spoken by the user, and then the system will do some processing to give the user a reply.
There is an important difference between the dialogue system we are talking about today and the traditional question and answer system. The dialogue system maintains the context. When doing a dialogue, there is a context scene. In the context of the process, some dialogue states need to be controlled. Completely understand the user's intentions.
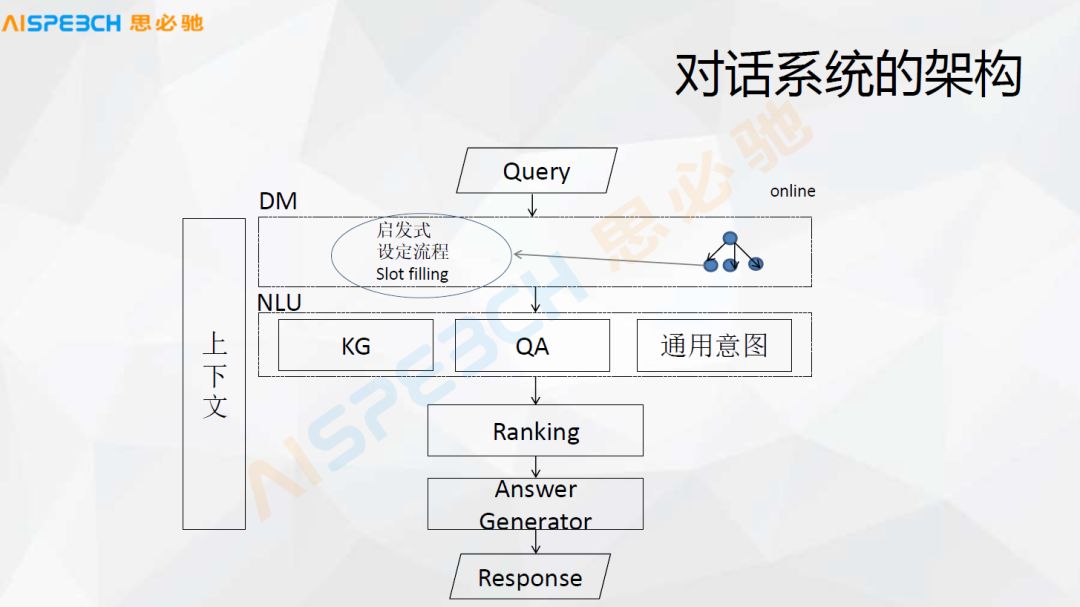
For example, the user asks whether it will rain tomorrow? The system will do some preprocessing, that is, some natural language processing feature processing, such as word segmentation, part-of-speech tagging, named entity recognition modules, some entities can be identified here, for example, the time inside is tomorrow, and the weather phenomenon is next Rain, this is what named entities can do.
After the preprocessing of the features and the recognition of the named entity, then enter the formal understanding of this sentence. The first is that each question of the user needs to be judged in a field. Generally, this field judgment is made because various scenarios are supported in the dialogue system. First, the user’s sentence is limited to a fixed scenario, and then the user’s sentence is limited to a fixed scenario. Do the corresponding follow-up treatment.
Generally, there are various ways to judge the domain, whether it is writing templates or some classification algorithms. For example, if we send this sentence to a classifier, it may be able to judge that it is related to a weather domain. Here, through Slot Filling, it can get an intent in the weather field. This intent field is the weather field and has its location and time. Of course, this sentence does not mention the location, because generally such a system will obtain a default location or default city through sensors or positioning information, or IP, or information about various device-related scenes. Information, and then we get a structured intention.
This structured intent is then sent to a dialogue management or dialogue state tracking module. The dialogue state management will make a judgment on whether the slot in the current field, such as the weather field, is satisfied. The field of weather is relatively simple. I found that this sentence has actually met its field intentions, time, and location, and then added these slots.
According to the supplemented information, it is actually a structured information. According to its time, location, and weather phenomenon, then go to the back-end data service to do a search to find out the real weather, such as if it needs rain tomorrow or is it The information such as sunny days is taken out, and then an answer is generated, a module such as Response Generation, and then a more natural sentence is generated. For example, it means that the day may be a sunny day, and then it means that the day is a sunny day. If it is more natural, maybe Said it is a good time to travel, like this, the whole process is probably like this, in fact it is a relatively simple process.
Through this process, I want to share with you the basic structure of the dialogue system. First, it has to process a user's Query, and then it has to go through a dialogue management module. This dialogue management is actually to maintain contextual information. The following is the understanding of an intention. There may be various ways to understand this intention, including knowledge base or knowledge graph, including the form of question and answer, this question similarity matching, and some general and various other intentions. Understand, including these things that are intended to be classified.
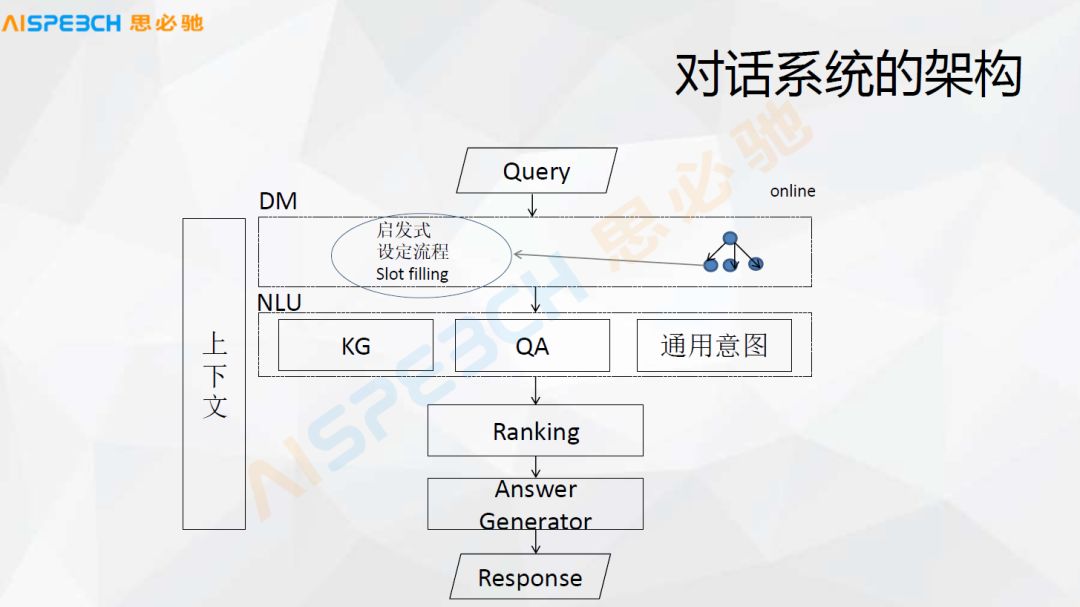
In this, the dialogue management is in this. Under normal circumstances, dialogue management is actually something similar to a flowchart. For example, in the weather just now, it is actually called Slot Filling. After a few pieces of information are filled, That's it. Then in some other conversations, such as a typical customer service, in fact, it is generally in a specific scenario of customer service, such as a certain financial business in the financial field or a user inquiring about a financial product, such as insurance products, certain An insurance product, it has some information, it is actually in the form of a flowchart.
There is also a heuristic dialogue that we will mention later. The combination of these forms is actually a dialogue management. Nowadays, the general system may be dealing with a certain kind of dialogue, either Slot Filling, or a set process, or a heuristic. There may not be too many integrations.
Continuing in this picture, I just mentioned that dialogue management is DM. The understanding of dialogue is the knowledge base, Q&A pairs, and some common ones, such as complaining, a common state, and under normal circumstances it may be a way of classification. After the understanding of this kind of NLU, after each module achieves this NLU, it needs to make a choice, because in various systems, the user may find an answer in a word, which answer we choose, so Just do a sort, after sorting, an answer is generated, and finally a reply is given to the user.
Of course, there is also a module on the side that is context management. It will be used a lot in dialogue management, NLU, sorting and answer generation modules, and it will maintain some contextual information. Of course, the structure of this picture is relatively simple, but there are actually a lot of things in each one. We will look at the specific content later, and finally we will look back at this picture, and there may be something different.
Before looking at it, let’s summarize the current status of some dialogue robots, how to evaluate general dialogue robots or its current state, general evaluation standards, our evaluation of robots is not very good, let’s make a system or do an academic In general, how to measure the effect of this robot is actually a very important matter. We need to set a standard before doing this.

Generally speaking, there are several main evaluation things in a dialogue system. One is the accuracy rate. The accuracy rate may be based on whether some questions and answers are correct or incorrect, or whether the dialogue answers are correct or incorrect. For example, this dialogue has been conducted for ten rounds. If you are right several times and wrong several times, you can directly make a judgment of zero and one, and then calculate the accuracy rate.
The other one is manual scoring, because it may not be an absolute zero-one judgment during this dialogue. Sometimes the answer it gives may not be so reasonable, but it is acceptable to a certain extent, so people can generally give it a mark. Score, say 1 to 10 points or 1 to 5 points, give a score, and finally give the robot a comprehensive score.
Academically, it may learn from some other system standards, such as perplexity or BLEU value to give some scores. Generally, this standard is more to measure this sentence in a limited data set, and this sentence is generated. Its language fluency may be more measured from the perspective of language fluency. Of course, the perplexity or BLEU value has the advantage of being able to judge automatically, but the disadvantage is that it is actually difficult to strictly judge from the semantics. Judge whether this system is good or bad.
In some extremely narrow areas, such as ordering food, or even narrower, such as ordering a pizza or coffee, or making a phone call, this is a very narrow area. In fact, now machine learning methods and template methods can be used. To a better accuracy.
Machine learning or deep learning, but deep learning in this scenario also relies on a relatively large amount of data. Compared with this scenario, because in this kind of experiment, its scenario is generally relatively small. If there are many scenes, in a more complex scene, the effect of deep learning may not be very good now, that is, in the scene of multiple rounds of dialogue, and there are multiple scenes mixed.
In addition, in some larger areas, such as customer service, the customer service scene, it is generally for a company's customer service, a company's customer service may involve several products, even a category of products will also involve this category With different product lines and various models, customer service is a relatively wide area.
Now whether it is deep learning or other traditional machine learning, if deep learning is used as a whole, its accuracy rate is relatively low, and it is rarely possible to achieve more than 50%, which is in a relatively large field. . So now in the field of customer service, many systems are based on search styles or templates. The search style is that it has prepared some standard question and answer pairs, because when companies do their own customer service, they generally accumulate some of their own questions. For the standard questions and answers of your own products, a user’s question is here to find the most similar question, and then give it an answer. This method is currently used more frequently.
The other is the template. Manually write some regular templates or semantic templates, and then explain the main information contained in the user’s question, and then give an answer to an intent. In these fields, In larger areas, machine learning algorithms still have some challenges, even if using templates, it also has a lot of challenges, because when there are more templates, it will have conflicts and problems that are not easy to maintain.
â–ŒHeuristic dialogue system
The heuristic dialogue system is a heuristic dialogue system we are working on. The heuristic dialogue system now has some similar concepts, such as active dialogue. The heuristic dialogue system proposed by Spitz may be mainly in this way. In some Many times in the enterprise scenario, the user is actually facing a dialogue robot. He is not sure what kind of questions he can ask, what is the abilities of the robot, what kind of questions it can answer, or the user probably knows what he wants. Something, but he still has to think a little bit about asking questions and asking him to ask a lot of questions.
Heuristic dialogue is probably such a process. It actually allows this dialogue to continue through some of the connections behind these issues. Of course you say you don't want to understand and then it ends. This is a basic concept.
Let's take a look at the basic characteristics of heuristic dialogue. First, actively guide the dialogue interaction according to the user's question. The user asks a question, and the system will list some related questions based on this question or ask the user if he wants to understand it. The user’s question is connected to the knowledge point in many ways. Of course, after this dialogue, we call it the knowledge point. In the form of a knowledge point, connecting a knowledge point may be for a specific problem, which may be different. Ask the law, we all think it is a knowledge point.
In many forms, it refers to the current common form. It may be a question-and-answer pair form. Behind the dialogue system may be a question-and-answer pair form, or it may exist in the form of a knowledge graph, but they are connected. They are unified, and they are all managed with a kind of knowledge point.

If a knowledge point is intuitively understood, we can think of it as something like a question-and-answer pair or an entity-related attribute in the knowledge graph. Between these knowledge points or between questions, it is integrated through topics, and topics are actually for users. An invisible concept, it is to make recommendations, because after we connect the question through the topic, the latter heuristic dialogue actually makes some choices based on the topic. The user asks a question, and we put the problem The knowledge point of the knowledge point, the topic that this knowledge point is on, find some related topics based on this topic, and then find some corresponding questions under those topics, and then recommend them to users.
There are some semantic or logical relationships between topics, and how these topics are organized later will be discussed in detail. The entire dialogue process may be based on the overall planning and jumping of topics. These are some of the characteristics of the entire heuristic dialogue now.
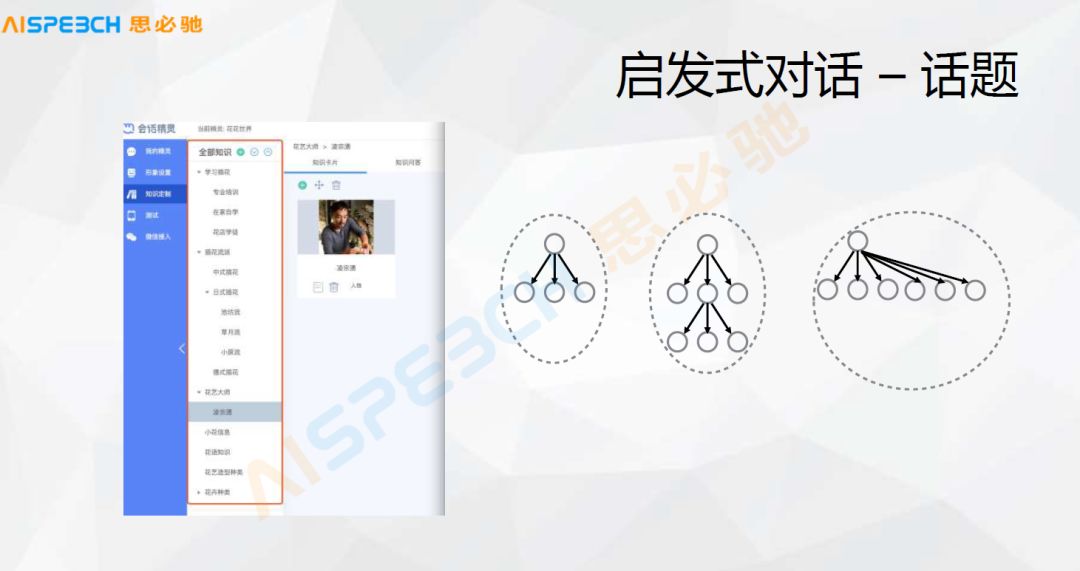
This is a specific example, this is the form of a product, that is, the organization of this topic. For an enterprise customer, if it wants to build a dialogue system, it can set some topics artificially. This topic is organized in a tree structure. For example, there is a topic about flowers, such as how to learn. Flower art, various flower art-related information, for each topic, the orange part is the organization of the topic, topic tree, and the user can set the organization of such a topic. Under this topic, the user can set some under each topic, such as the master of flower art, the user of the master of flower art can define some information related to the people below it, and then list the related information of these people.
A terminal user can ask for this information about people, so there are probably several forms of topics. First of all, in the form of the figure on the right, there may be two or three such topics under a certain topic. Of course, this topic can also have Level, it can have subtopics and grandson topics. This hierarchical structure can be organized and expanded. Of course, there can be many topics under a topic, an organization form of this topic, and these basic concepts.
â–ŒKnowledge management in dialogue system
Let’s take a look at how the knowledge in the dialogue system plays a role in dialogue understanding and dialogue management. Later, I will combine the existing technology, the existing common technology in the dialogue, Then, together with the heuristic dialogue, we will introduce the knowledge management in the dialogue system.
Let's first look at a few examples. Some of the problems that robots may encounter in understanding language will give you an intuitive sense of what problems may be encountered. For example, in the process of comprehension, the robot understands the language, such as the input "Is Tianjin suitable for car wash today?" If it is voice or pinyin input, there may be such a problem, "Is Tianjin suitable for car wash today?" may be the same as " Today, Tianjin Hexi", there is a Hexi district in Tianjin, and you might get misunderstood, and you might make mistakes from pinyin to characters. In fact, this is very similar.
This is because we may have some language problems. When machines do this, it is actually difficult to judge. People have some background knowledge and contextual knowledge.

Let’s take a look. There are so many questions listed just now. Generally speaking, we will do the core of this dialogue. Just now we have seen the three core parts of the dialogue system in the initial architecture diagram. One is natural language understanding and the other It is the three parts of dialogue intention understanding, dialogue management and dialogue answer generation.
Everyone is more concerned about the first two aspects, the understanding and management of dialogue. Perhaps the most common understanding of this part is a rule-based system. For example, we write a pattern, scientific researchers, time, and published articles, similar to this, There are some dictionaries and rules organization in this rule system. Of course, this has a series of rule organization problems. In fact, it is also a relatively large project, but we may think that it is a relatively simple one from the point of view of algorithms or our understanding. The way, of course, is very difficult to maintain with more rules.

Another possibility is to classify it by intention, such as classifying it through some machine learning methods. For example, if we do something simple, such as weather, the dialogue system only needs to understand that it is weather, and then we broadcast a weather forecast to it. In many scenarios, users can also accept it. The system does not understand the specific things in it, but only understands it. An intention, and then give it a broadcast. The common classification algorithms can be used here.

The other is the question retrieval method, which is actually used extensively in small chats or customer service. We talk about small talk. In fact, academically speaking, a lot of research may be doing deep learning small talk, but in the actual scenario, many of the small chats are also retrieved through question-and-answer retrieval. Of course, it requires a large number of question-and-answer pairs. These The question and answer pairs are all sorted out manually in advance, which is a relatively labor-intensive thing, and its coverage is limited.
The general way to do this is to first pass an inverted index. After the user problem comes, retrieve a set of questions, then make a candidate for it, and then do some sorting. The sorting algorithm may have various weights. There are traditional learning to rank, and deep learning algorithms for deep semantic matching. We can look at a few examples of these algorithms in detail later.

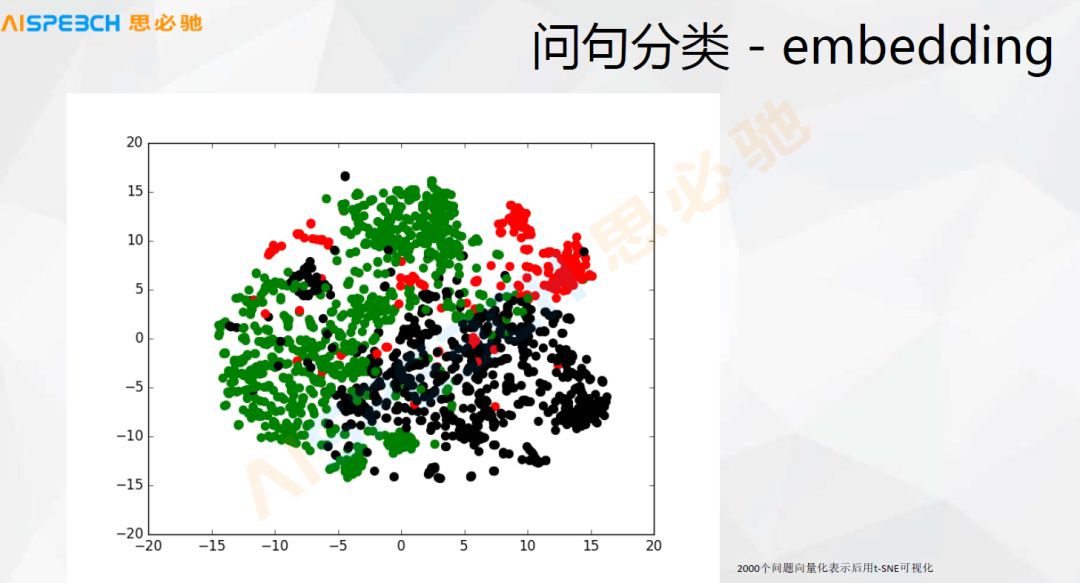
Question classification also has some direct deep learning, such as embedding. Actually, deep learning. For example, the Sequence to sequence model mentioned above can directly embed the user’s question into a vector. We can actually do it directly by taking this vector. For the classification or similarity calculation of some question sentences, this picture is about more than 2000 users' questions, and then an embedding is made, that is, an embedding is made using Sequence to sequence.
At this time, use this visualization tool to visualize it. We can see that it can probably be separated. These are three types of problems. In fact, they are indeed three types of problems. Although there are some overlaps between them, now This deep learning method is still quite capable of modeling such things, and the basic problem categories can still be distinguished.
In the picture below, these algorithms in this basic deep learning now have a very basic model, the Sequence to sequence model, which is based on every word the user says, for example, ABC is an input word ABC is the input question, A is a word, B is a word, C is a word, and its output may be XYZ, it sends it to the Sequence to sequence neural network, A is a word After entering, there is a model of RN. It does such an embedding, and it actually reaches ABC, and then eos, which is the end of the sentence.
After the end, the middle layer of the neural network is a W. This W can represent the semantic meaning of the sentence. Use this W to decode an answer. After a lot of data training, you can actually generate an answer. Generative chats are possible. This is mainly done. This model, including the representation W in the middle, can actually be used to classify question sentences or calculate the similarity of question sentences.

This is a basic model. Now we are doing question sentences. We just mentioned that there are a large number of actual use of question sentence similarity matching. One way to do it is to calculate the sentence similarity. This picture is a sentence similarity. The basic model of degree calculation, these are all existing methods.
For example, use LSTM to encode a sentence. The basic model of this LSTM is similar to the previous Sequence to sequence encoding stage. A user's problem and a system problem, both of which go through an LSTM, and this X represents Input, H represents the hidden layer in the middle of the model. The user's sentence is encoded into a state of h3(a) through LSTM, and there is a standard problem (the retrieved problem), which is encoded into In such a state of h4(b), two calculations of a distance can be sent to a classifier to make a similar or dissimilar judgment.
This method is to convert the user into a classification problem, a two classification problem, the user's problem is similar or dissimilar to the problem in our standard library, and then make a judgment. This can also be done in this way. This is a more classic way. In fact, its effect is quite good, and it is quite suitable in many scenarios.
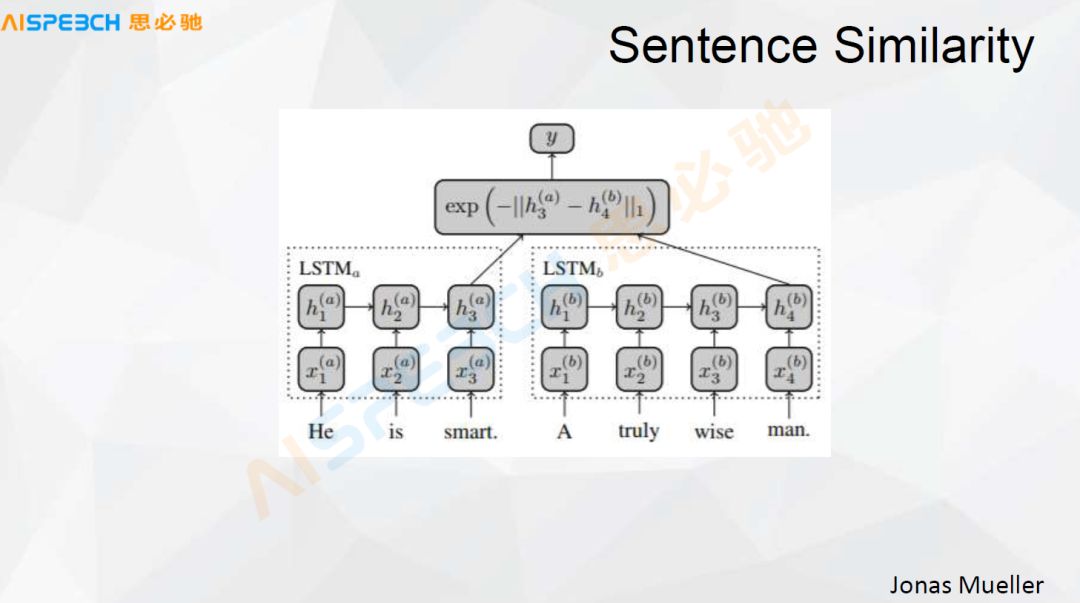
Let's take a look at the following article. I think this article is a classic one in terms of similarity calculation, and it does a better job. The left side of it is the input. For example, u_1, u_n-1, u_n are the user's input, and u_1 to u_n are the entire context of the user's input. He may have said many sentences. r is the response response.
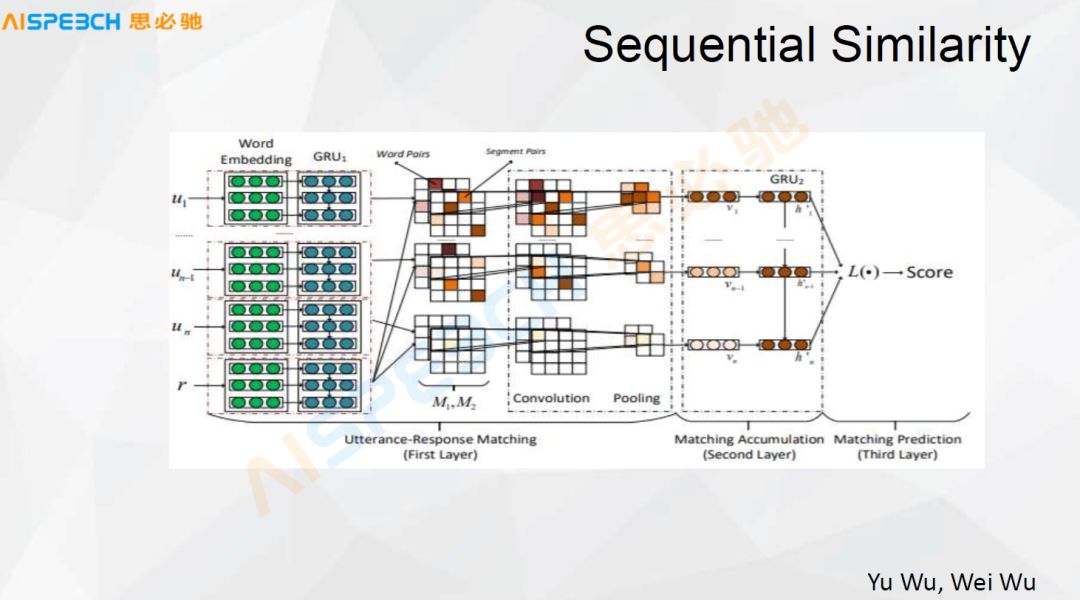
This context passes through a Word Embedding, each of which can be Embedding into a word vector representation, and then passes through a GRU or LSTM, and then encodes it into a vector. Here is a more complicated operation. In the middle part, M1M2, it crosses the user's input and answer to calculate an inner product. They are all vectors, and they are actually matrices. Perform an inner product mixing operation between them, and then pass through CNN after sufficient crossover. CNN then passes through a Pooling. After Pooling, it passes through a GRU similar to this side, and finally outputs a score.
The biggest difference between this method and the LSTM method just now is that first of all, the number of layers is increased, because the front is a GRU, and the last is a GRU. There is an additional CNN layer in the middle. The function of this CNN layer is actually to solve the problem. Fully mix the information with the answer, find the similar or combined points in it, and then give an answer. The effect of this model in many scenarios is relatively good. In some experiments, it is actually relatively good, but its problem is that because it has undergone a very thorough mixing, we can see that it affects the input There are certain requirements. This input is relatively long and its information is relatively sufficient. This is better. But in some dialogue scenarios, when the dialogue is relatively short, its effect is actually limited. This is one way.
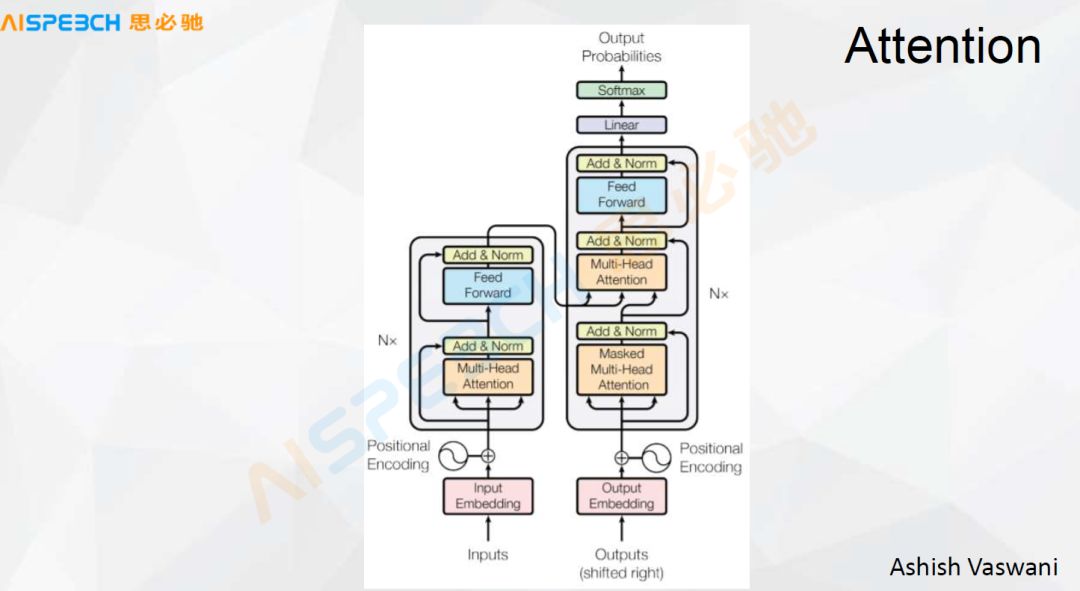
This picture is in an article by Google. It only uses Attention to solve. For example, Input and Output are two places. After a series of Attentions, they are finally output, and we make a classification decision. When we use the Attention model and the multi-layer Attention model to do this classification task, when the problems are relatively short in some relatively short text scenarios, its effect is actually better. In fact, these models may not be omnipotent. Each model has its applicable scenarios. Based on the data, we can see in which scenarios it is better or has its advantages. Each model has its strengths and weaknesses.
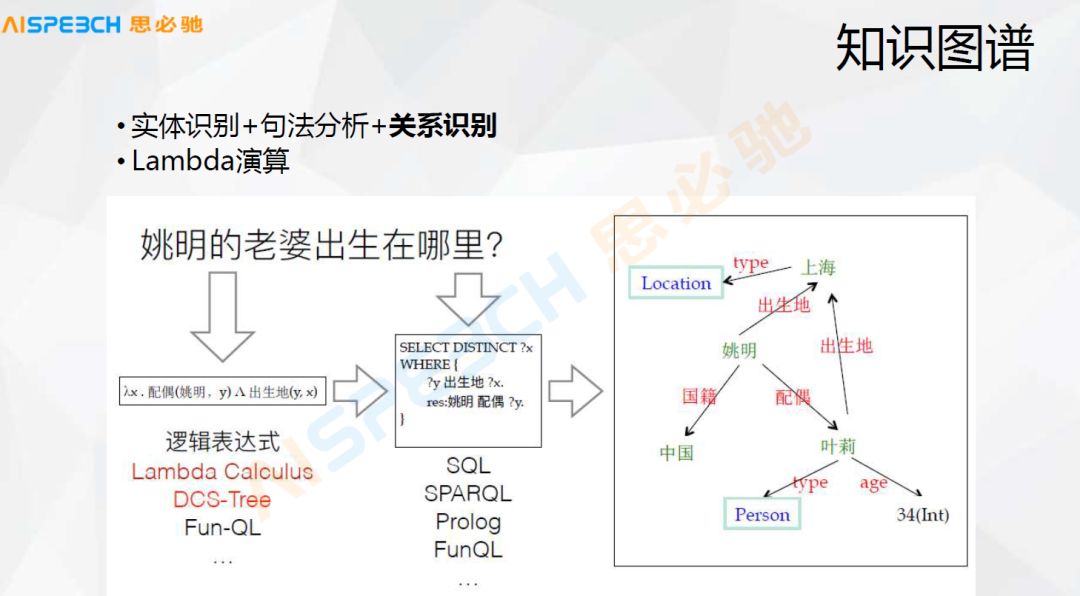
There are also some ways of knowledge graphs. The most intuitive possible knowledge graph is made through some logical expressions. For example, a simple question is where is Yao Ming’s wife born? The knowledge graph stores Yao Ming and his Spouse Ye Li, this method is relatively simple for us to understand. It is to do such a search, but when the knowledge graph is relatively large, it is actually difficult to do the question and answer on the knowledge graph. The main reason is that it is difficult for the user’s expression to match strictly with the things in the knowledge graph. Generally, in this way, a user’s question is strictly parsed out of the various entities and their relationships in the question, and then these are converted into A logical expression, through this logical expression to find in this knowledge graph. This method is also very commonly used.
I just introduced the main methods of understanding, but now there are many ways to integrate, I integrate the above methods, and then do an integrated learning, such as the method of question understanding, the way of question and answer, is retrieval, knowledge graph, embedding Yes, it can be used for Q&A. Task-based Q&A may have rules, embedding, or classification. Complex problems may be that there are many problems in the customer service, which are actually quite complicated and relatively long in length. You can use this Classification or retrieval can also be done in a more rigorous way of semantic analysis. These different methods and algorithms are integrated. In fact, many of them are doing this now, and the effect is still quite good.

That is, we are making a model to make a choice. For example, we have made three or five models to understand. The user will understand all these models in one sentence. After understanding, we will do an integration, and then we will do the final integration. The output of the integration is actually to make a choice. The answer to which model to use, of course, there are mainly two ways of integration, one is the assembly line, I arrange these models in a sequence, whichever model is solved, I will come out, I will Get the answer out, and then stop going back. The other is model integration. Every model goes, and then a decision is made to determine which model to choose.
The above is the part about NLU in the dialogue, and the other part is about the knowledge management in the dialogue, or the knowledge management in the dialogue management, the part of the dialogue management.
Dialogue management is generally like this. When we have context, dialogue management means that the user may be able to analyze an intention at present, and sometimes we cannot even analyze an intention at present. For example, if the user mentioned Shanghai, we actually don’t know what the user said about Shanghai. If it was about the weather, then Shanghai was related to the weather. If it was about booking tickets, then Shanghai was related to booking. There is the intention of a current user, even this is not an intention, and then there are the above, some of the above are in which field, there is user information, this sometimes may also have some long-term user information, according to these The information makes some behaviors, whether to reply or refuse, or to ask the user for supplementation, the user needs to add some information.
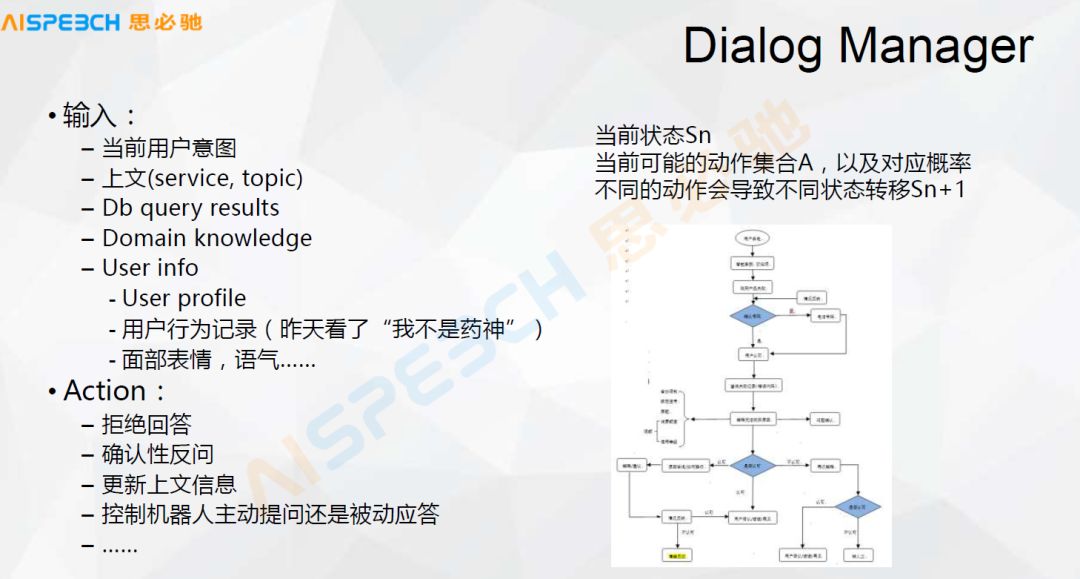
There are several main forms of dialogue management. One is slot-based. Slot may be a filling slot. If there are three slots, time, place, and weather phenomenon, I just fill it out. Ask the user which one. Another problem that is not particularly easy to solve with slots is that some processes are very complicated, especially in customer service. For example, the scene in this picture, this is a customer service scene, and its process is very complicated. When the user arrives at a certain place, He needs to judge the information about this place, and then do the next step, which is the main thing of this dialogue management.

This picture introduces the most basic dialogue management, such as SlotFilling. It defines the ticket booking scene in advance if there is context or not, and then it has some contextual information how to control it. This scene is just mentioned. When it arrives, I won't elaborate on it.
There is also a topic-based dialog management in the heuristic dialog. First of all, the topic itself, because it introduces a new concept that is the topic. It introduces the topic in addition to the question asked by the user. The topic can be artificially created or it can be The system automatically calculates it, or the system guides the user to create it. This topic is what we saw when I talked about the heuristic dialogue at the very beginning. For example, the organization of some related topics about flowers can also be through some The way of learning is to explore the topics between the problems, especially in some enterprise service scenarios, because the enterprise itself has its own clear application scenarios, so it has some topics, and it has organized organizations about these topics.

Of course, there are actually many problems with topic organization. For example, we use a tree to organize these topics. How to organize this topic behind the system. For example, organize topics according to products and characters. All products are a topic, and all characters are a topic, but when I really want to ask this system, you will find that there is an overlap between products and characters, because Characters, such as those in the field of science and technology and those in the entertainment field, they may not have any cross-cutting fields, and it is not appropriate for us to put it under one topic. Therefore, the division of topics is actually cross-cutting. Of course, we show that under normal circumstances, it is organized in a tree-like way, so that it is easier for users to understand. But there are actually many crossovers behind its real management.
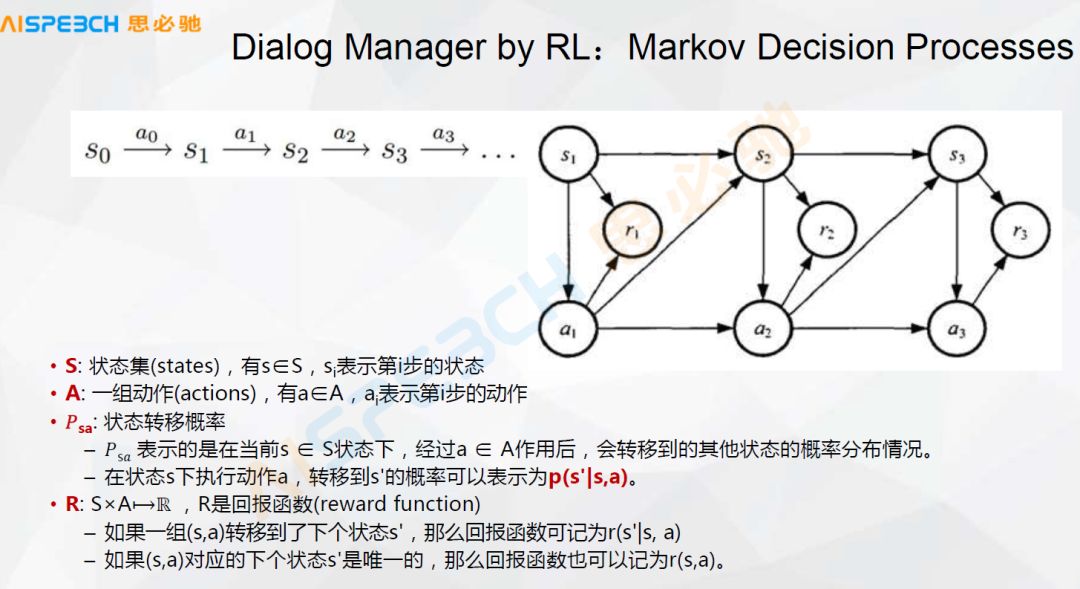
The management of dialogue, in general, we can think of it as this state. The process of state transition may be a typical Markov decision process. Here, S is a set of states, and A is a set of actions. In a certain state, it encounters something, and then what kind of response or what kind of action it needs to do, the way of machine learning may need to organize this dialogue into such a state, an important point here is There needs to be some return function.
For example, when intensive learning is doing this kind of dialogue, it is not necessarily doing dialogue management. When doing dialogue generation, there is also this kind of scene. That is to say, it defines one in the dialogue, it simulates multiple rounds, and according to a predetermined return function , And then make a judgment. This is dialogue management. Dialogue management can be done with intensive learning. In fact, reinforcement learning is to simulate multiple rounds of dialogue, and then come back to judge which step is appropriate for the current state.
This is a simple state that uses deep reinforcement learning to track the conversation state. For example, the user inputs a sentence, through speech recognition, it can have a state management, and then manage this state, and control its output through a strategy. Of course, one of the core parts of it is the Reward function. In the dialogue, the Reward function is very important. Under normal circumstances, it is not easy to define, because we are talking about what is appropriate and what is not appropriate. This It is not particularly easy to control.
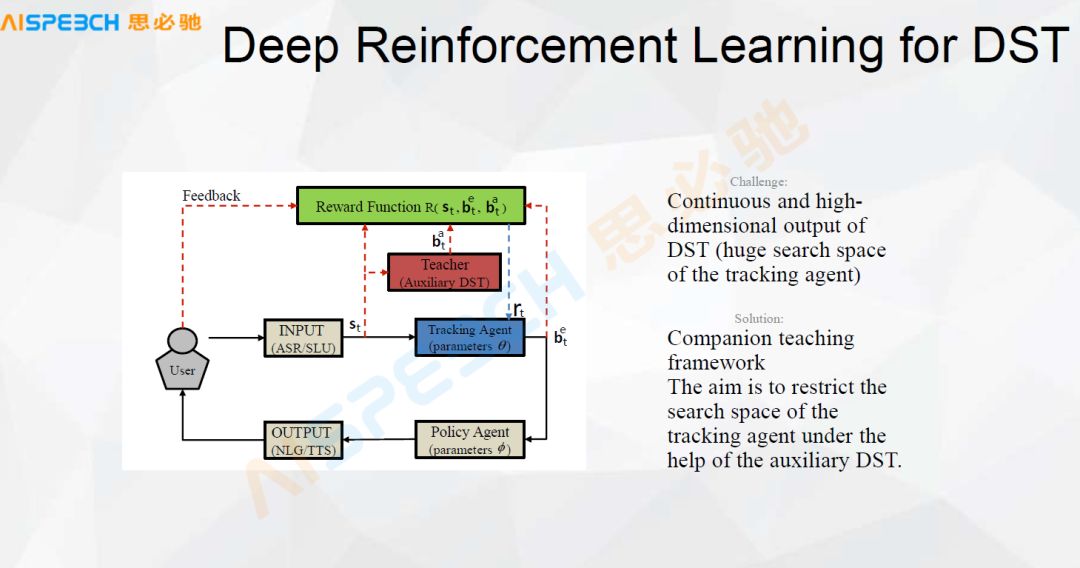
Let’s take a look at the use of reinforcement learning for dialogue. To briefly summarize, in a state S, it may have m operations. We don’t know which of these m operations can bring what kind of return, so we do an exploration , To explore the return of every possible operation, use this return to make a response, make a decision or make a score for this return.
In addition, it is also useful for adversarial networks, but there is a problem with the adversarial network, which is actually not easy to control. In some cases, the direction of these dialogues may be forced, and the stability of the adversarial network is also a problem. During this training process Stability is also an issue.

Whether it is deep learning or traditional machine learning, some methods or functions in dialogue NLU and dialogue management, the previous ones are all existing methods, how to do it, but there will be some problems in it, machine learning In many cases, if it is generative, it is difficult to control whether it is related or not, and it is difficult to judge. If it is a search type, the user will give it a search answer no matter what the user said. Whether the answer is for the user or not, the user said an irrelevant question, I may also retrieve it for it One answer, is the answer given or not? This is also a problem. In fact, knowledge is used here, which is very important in this process.
There are two types of knowledge here, one is the knowledge graph, the strict knowledge graph, and here is the part of KG. Others are language knowledge, such as language collocation, language grammar conversion, spelling problems, domain problems, in fact, some domain words, similar words, synonyms, these things have been developed in natural language for so many years In fact, a lot of knowledge in this area has been accumulated, but these things are actually difficult to integrate in deep learning.

Through the similarity calculation model mentioned above, we can complete the similarity calculation problem of natural language, but the answer we gave is very likely to be wrong, so after the characteristics of these languages ​​and the knowledge of KG,知识作为验è¯å€™é€‰çš„è¯æ®ï¼Œæ·±åº¦è¯ä¹‰æ¨¡åž‹ç»™å‡ºå¤šä¸ªå€™é€‰ç”案,我们对于这ç§å¯èƒ½çš„å„ç§ä¾¯é€‰ï¼Œé€šè¿‡çŸ¥è¯†å›¾è°±æˆ–者è¯è¨€çŽ°è±¡å¯¹å®ƒåšä¸€ä¸ªåˆ†æžï¼Œç„¶åŽåŽ»æ‰¾åˆ°ä¸€äº›è¯æ®ï¼Œè¿™äº›è¯æ®å†æ¥éªŒè¯åŽ»é€‰å“ªä¸€ä¸ªç”æ¡ˆã€‚å› ä¸ºä¸€èˆ¬æƒ…å†µä¸‹å¯¹äºŽç›´æŽ¥ç”¨ä¸¥æ ¼çš„çŸ¥è¯†å›¾è°±æ¥è§£æžä¸€ä¸ªé—®é¢˜çš„æ—¶å€™æœ‰ä¸€ä¸ªé—®é¢˜ï¼Œå¾ˆå¤šæ—¶å€™æˆ‘ä»¬æ— æ³•ä¸¥æ ¼åœ°åŽ»è§£æžå‡ºæ¥è¿™ä¸ªé—®é¢˜ï¼Œåªèƒ½è§£æžå‡ºæ¥ä¸€éƒ¨åˆ†ã€‚
COB Light
COB LED par light for theatre, productions, TV studio, stage
Description:
COB200-2in1 is a professional theatre fixture that utilizes a 200W warm-white and cold-white COB LED with a color temperature of 3200k-6000K. Users are able to creat a customized color tempreature via a DMX Controller or set directly on the display menu. It offers a high-power light output with rich hues and smooth color mixing for stage and wall washing. The double bracket makes installing easily and versatile.
Our company have 13 years experience of LED Display and Stage Lights , our company mainly produce Indoor Rental LED Display, Outdoor Rental LED Display, Transparent LED Display,Indoor Fixed Indoor LED Display, Outdoor Fixed LED Display, Poster LED Display , Dance LED Display ... In additional, we also produce stage lights, such as beam lights Series, moving head lights Series, LED Par Light Series and son on...
COB Light Series,Led Par Light,54 Led Par Light,Par Led Lights
Guangzhou Chengwen Photoelectric Technology co.,ltd , https://www.cwstagelight.com