Apache Spark is a fast, versatile computing engine designed for large-scale data processing. Spark is a general-purpose parallel framework of Hadoop MapReduce open sourced by UC Berkeley AMP lab (AMP Lab of UC Berkeley). Spark has the advantages of Hadoop MapReduce. But unlike MapReduce, Job intermediate output can be It is stored in memory, so you no longer need to read and write HDFS, so Spark can be better applied to data mining and machine learning and other iterative MapReduce algorithms.
Spark is an open source cluster computing environment similar to Hadoop, but there are some differences between the two. These useful differences make Spark perform better on some workloads, in other words, Spark is enabled. In addition to providing interactive queries, it also optimizes iterative workloads.
Spark is implemented in the Scala language and uses Scala as its application framework. Unlike Hadoop, Spark and Scala are tightly integrated, and Scala can manipulate distributed datasets as easily as local collection objects.
Although Spark was created to support iterative jobs on distributed datasets, it is actually a complement to Hadoop and can run in parallel in a Hadoop file system. This behavior is supported by a third-party clustering framework called Mesos. Developed by the University of California, Berkeley AMP Labs (Algorithms, Machines, and People Lab), Spark can be used to build large, low-latency data analysis applications.
HadoopHadoop is a distributed system infrastructure developed by the Apache Foundation.
Users can develop distributed programs without knowing the underlying details of the distribution. Take full advantage of the power of the cluster for high-speed computing and storage.
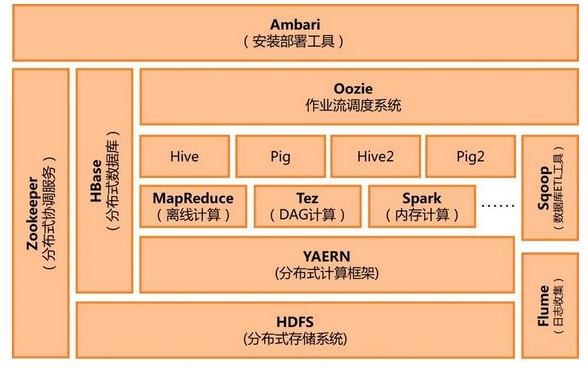
Hadoop implements a distributed file system (Hadoop Distributed File System), referred to as HDFS. HDFS is highly fault-tolerant and designed to be deployed on low-cost hardware; it also provides high throughput to access application data for large data sets (large data) Set) application. HDFS relaxes the requirements of POSIX and can stream access data in the file system.
The core design of Hadoop's framework is HDFS and MapReduce. HDFS provides storage for massive amounts of data, and MapReduce provides calculations for massive amounts of data.
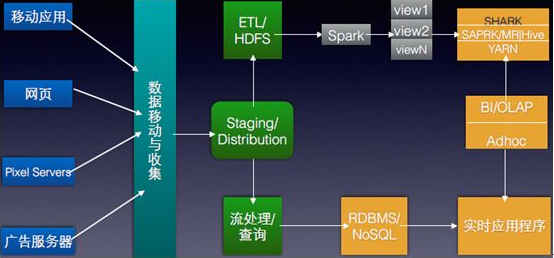
The level of problem solving is different
First, both Hadoop and Apache Spark are big data frameworks, but their respective purposes are different. Hadoop is essentially a distributed data infrastructure: It allocates huge data sets to multiple nodes in a cluster of ordinary computers for storage, meaning you don't need to buy and maintain expensive server hardware.
At the same time, Hadoop also indexes and tracks this data, making big data processing and analysis more efficient than ever. Spark is a tool that is designed to process large data stored in distributed storage. It does not store distributed data.
The two can be divided
In addition to providing HDFS distributed data storage for everyone's consensus, Hadoop also provides a data processing function called MapReduce. So here we can completely abandon Spark and use Hadoop's own MapReduce to complete the data processing.
On the contrary, Spark does not have to rely on Hadoop to survive. But as mentioned above, after all, it does not provide a file management system, so it must be integrated with other distributed file systems to function. Here we can choose Hadoop HDFS, but also choose other cloud-based data system platforms. But Spark is still used by Hadoop by default. After all, everyone thinks that their combination is the best.
The following is the most concise and clear analysis of MapReduce extracted from the Internet:
We have to count all the books in the library. You count the number 1 bookshelf, I count the number 2 bookshelf. This is the "Map". The more we have, the faster the books are.
Now let's get together and add the statistics of everyone together. This is "Reduce."
Spark data processing speed spike MapReduce
Spark is much faster than MapReduce because it handles data differently. MapReduce processes the data step by step: "Read data from the cluster, perform a process, write the results to the cluster, read the updated data from the cluster, perform the next processing, and write the results to the cluster. Wait..." Bork Allen Hamilton's data scientist Kirk Borne analyzes this.
In contrast, Spark, which does all the data analysis in memory in near real-time time: "Read data from the cluster, do all the necessary analysis, write the results back to the cluster, and finish," Born said. Spark's batch processing speed is nearly 10 times faster than MapReduce, and the data analysis speed in memory is nearly 100 times faster.
If the data and result requirements that need to be processed are static in most cases, and you have the patience to wait for the completion of the batch, MapReduce is also completely acceptable.
But if you need to analyze the convection data, such as those collected from the factory's sensors, or if your application requires multiple data processing, then you should probably use Spark for processing.
Most machine learning algorithms require multiple data processing. In addition, Spark's application scenarios are usually used in the following areas: real-time marketing activities, online product recommendations, network security analysis, and machine diary monitoring.
Disaster recovery
The disaster recovery methods of the two are very different, but they are very good. Because Hadoop writes the data after each write to disk, it is inherently flexible to handle system errors.
Spark's data objects are stored in a distributed data set called RDD (Resilient Distributed Dataset). "These data objects can be placed either in memory or on disk, so RDD can also provide disaster recovery capabilities," Borne said.
Wire harness refers to a product assembled by wires and connectors. There are many brands of connectors, including terminals, plastic shells, and plugs.
Wire harness is one of the fastest-growing, most market-demanding and most convenient products in today's electronic and information age industries. Wire harnesses are widely used in military equipment and other equipment. At present, the wire harnesses we have come into contact with are made of various wires and cables according to different circuit numbers, hole numbers, position numbers and electrical principle requirements. The assembly of the wire harness composed of the components, the external protection and the connection of the nearby system, but the product application of the wire harness is mainly in the functions of four parts. According to the application scenario, various functional cables will be selected for matching applications. Screen drive wire harness, control wire harness, power control, data transmission, etc., the classification of product categories will be more, roughly including railway locomotive wire harness, automobile wire harness, wind power connection wiring harness, medical wire harness, communication wire harness, household wiring harness, industrial control Cable Assembly, etc. ;The wiring harness is a variety of complete equipment, instrumentation, and basic equipment that is indispensable for signal and power transmission. It is a necessary basic product in the future electrification and information society. The following are common wiring harness products. You have seen several ?
1. The screen driving wiring harness is mainly used in the driving lines of various display screens, as long as it is used in the field of display screens;
2. Control wire harnesses are mainly used to connect circuit boards to control electrical signals, financial equipment, security equipment, new energy vehicles and medical equipment;
3. Power control lines, such as switching power lines, computer power lines, etc;
4. Data transmission line, upload and download signals, such as HDMI, USB and other series.
Kable-X has passed ISO9001 quality system certification, UL certification, ISO13485 medical quality system certification, ISO/TS16949 automotive quality system certification, etc.
We focus on customized high-end wiring harnesses in the fields of industry, medical, new energy, vehicle, and communication. Our team has wire harness R&D capability and more than 20 experienced wire harness engineers.
Welcome to consult.


Custom Wire Harness, China Wire Harness, Industrial Wire Harness, Energy Storage Wire Harness, Vehicle Wire Harness
Kable-X Technology (Suzhou) Co., Ltd , https://www.kable-x-tech.com