Text Data Analysis (1): Basic Framework
In the basic framework of text data analysis, we have involved six steps:
data collection
Data preprocessing
Data Mining and Visualization
Model construction
Model evaluation
Although the framework needs to iterate, we first think of it as a linear process:
Modified text data processing framework (still very simple...)
Obviously, the text data preprocessing is located in the second step of the framework. This step contains the following two detailed steps:
Preprocessing on raw text corpora to prepare for text mining or NLP tasks
Data preprocessing is divided into several steps, some of which may or may not apply to a given task. But usually it is one of tokenization, normalization, substitution.
Usually, we will select a pre-prepared text, perform basic analysis and transformation on it, and leave more useful text data to facilitate more in-depth and meaningful analysis tasks. The next step will be the core work of text mining or natural language processing.
So repeat again so that the three main components of text preprocessing are:
Tokenization
Normalization
Substitution
In the process of introducing preprocessing methods below, we need to keep these three concepts in mind.
Text preprocessing framework
Next, we will introduce the concept of this framework without involving tools. In the next article we will go down to the installation of these steps and see how they are implemented in Python.

Text data preprocessing framework
1. Tokenization
Tokenization is the process of breaking a long string of text into small pieces or tokens. Large segments can be segmented into sentences, sentences can be segmented into words, and so on. Only after tokenization can the text be further processed. Tokenization is also called text segmentation or lexical analysis. Sometimes, segmentation is used to represent the process (such as paragraphs or sentences) of writing small pieces of text. And tokenization refers to the process of turning text into words.
This process sounds straightforward, but it is not. How to identify sentences in larger texts? Your first reaction must be "use punctuation."
Indeed, the following sentences are easily understood using traditional segmentation methods:
The quick brown fox jumps over the lazy dog.
But here's what this sentence says:
Dr. Ford did not ask Col. Mustard the name of Mr. Smith's dog.
and this:
"What is all the fuss about?" Asked Mr. Peters.
The above are just simple sentences. What about the words?
This full-time student isn't living in on-campus housing, and she's not wanting to visit Hawai'i.
We should realize that many strategies are not just for sentence segmentation, but rather what should be done after deciding on the boundary of the segmentation. For example, we may employ a segmentation strategy that (correctly) identifies the specific boundary identifier between the tokens of the word "she's" as an apostrophe (single-space-marked strategies are not sufficient to identify this). But we can choose from a variety of strategies, such as keeping punctuation in one part of the word or giving it up. One of the methods seems to be correct and does not seem to constitute an actual problem. But think about it, we need to consider other special circumstances in English.
That is, should we keep the end-of-sent separator when we segment the text into sentences? Do we care where the sentence ends?
2. Normalization
Before further processing, the text needs to be normalized. Normalization refers to a series of related tasks that can place all text in the same horizontal area: convert all text into the same instance, delete punctuation, convert numbers to corresponding text, and so on. Normalizing text can perform multiple tasks, but for our framework, there are three special steps to normalize:
Stemming stemming
Lemmatizatiion
other
Stemming
Stemming is the process of deleting affixes (including prefixes, suffixes, infixes, and rings) to obtain the word stems.

Lexical reduction
Lexical restoration is related to stemming. The difference is that lemmatization can capture stem-based canonical word forms.
For example, stemming the word "better" may not produce another root word. However, if you do a word form reduction, you get:
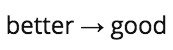
other
Lexical restoration and stemming are the main parts of text preprocessing, so these two items must be taken seriously. They are not simply textual operations but rely on grammatical rules and detailed understanding of the rules.
However, there are many other steps that can help process texts and make them equal status, some of which are simply replaced or deleted. Other important methods include:
Lower all letters into lowercase
Delete numbers (or replace numbers with corresponding text)
Delete punctuation (usually part of tokenization, but still need to be done in this step)
Delete blank space
Delete the default stop words
Stopwords are words that need to be filtered before further processing of the text, because these words do not affect the overall meaning. For example, the words "the", "and", and "a". The following example shows that even if a stop word is deleted, the meaning of the sentence is easy to understand.

Delete specific stop words
Remove sparse specific words (though not necessarily)
Here, we should clear up the text preprocessing to a large extent dependent on pre-built dictionaries, databases, and rules. In our next article on preprocessing with Python, you will find these support tools useful.
3. Noise removal
Noise removal continues the framework's alternative task. Although the first two main steps of the framework (marking and normalization) are usually applied to almost any text or project, noise removal is a more specific part of the preprocessing framework.
Again, keep in mind that our process is not linear, and the process must be performed in a specific order, depending on the circumstances. Therefore, noise cancellation can occur before or after the above steps, or at some point in time.
Specifically, assuming that we obtained a corpus from the Internet and stored it in the original web format, we can assume that the text may have HTML or XML tags to a large extent. Although this thinking about metadata can be part of the process of text collection or assembly, it depends on how the data is captured and collected. In the previous article, I briefly explained how to get raw data from Wikipedia and build a corpus. Since we control the process of data collection, it is also feasible to handle noise at this time.
However, this is not always the case. If the corpus you are using is very noisy, you must deal with it. 80% of the data analysis results are in data preparation.
The good news is that pattern matching can be used at this time:
Delete file title, footer
Remove HTML, XML, and other tags and metadata
Extract valuable data from other formats (such as JSON) or databases
If you are afraid of regular expressions, this may become part of the text preprocessing
The boundaries between noise cancellation and data collection are blurred, so noise cancellation must be done before other steps. For example, the text obtained from a JSON structure obviously eliminates noise before tokenization.
Wuxi Doton Power , http://www.dotonpower.com