With the popularity of machine learning in recent years, especially the deep learning of the fiery. Machine learning algorithms are becoming more and more popular in many fields. Recently, the author advertised an anti-cheat algorithm in an advertising company. I thought of the anomaly detection algorithm, and the Internet research found that there is an algorithm that is very popular. That is the algorithm Isolation Forest, referred to as iForest.
In 2010, the team of NTU Zhou Zhihua proposed an abnormality detection algorithm, Isolation Forest, which is very practical in the industry, with good algorithm effect and high time efficiency. It can effectively process high-dimensional data and massive data. Here is a brief summary of this algorithm.
iTree construction
When it comes to forests, there are naturally trees. After all, forests are made up of trees. Before we look at Isolation Forest (iForest), let's take a look at how Isolation-Tree (iTree) is formed. iTree is a kind of Random binary tree, each node has two daughters, or a leaf node, none of which is a child. Given a bunch of data sets D, where all the attributes of D are continuous variables, the composition of iTree is as follows:
Randomly select an attribute Attr;
Randomly select a value of this attribute;
Classify each record according to Attr, place the record with Attr less than Value on the left daughter, and put the record greater than or equal to Value on the right child;
Then recursively construct the left and right daughters until the following conditions are met:
The incoming data set has only one record or multiple identical records;
The height of the tree reaches a defined height;

After the iTree is built, you can predict the data. The process of forecasting is to take the test record on the iTree and see which leaf node the test record falls on. The assumption that iTree can effectively detect anomalies is that abnormal points are generally very rare, and are quickly divided into leaf nodes in iTree. Therefore, a record x can be judged by the length of the path h(x) from the leaf node to the root node. Whether it is an abnormal point; for a data set containing n records, the minimum height of the constructed tree is log(n), and the maximum value is n-1. The paper mentions that log(n) and n-1 return One can't guarantee bounded and inconvenient comparisons, using a slightly more complicated normalization formula:
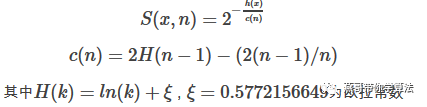
s(x,n) is the abnormality index of iTree in which x is composed of training data of n samples, and the s(x,n) value range is [0,1].
The closer to 1 is, the higher the probability of being an abnormal point;
The closer to 0, the higher the probability of being a normal point;
If most of the training samples have s(x,n) close to 0.5, there is no obvious abnormality in the whole data.
Because it is a randomly selected attribute, randomly selecting the attribute value, it is definitely not reliable to have a tree so casually, but combining multiple trees becomes powerful;
iForest construction
iTree figured out, let's take a look at how iForest is constructed. Given a data set D containing n records, how to construct an iForest. The iForest and Random Forest methods are somewhat similar. They randomly sample a part of the data set to construct each tree to ensure the difference between different trees. However, iForest is different from RF, and the sampled data amount Psi does not need to be equal to n. Far less than n, the paper mentioned that the sample size exceeds 256, the effect is not much improved, and the larger it will cause the waste of calculation time, why not like other algorithms, the more data, the better the effect, you can look The following two figures:
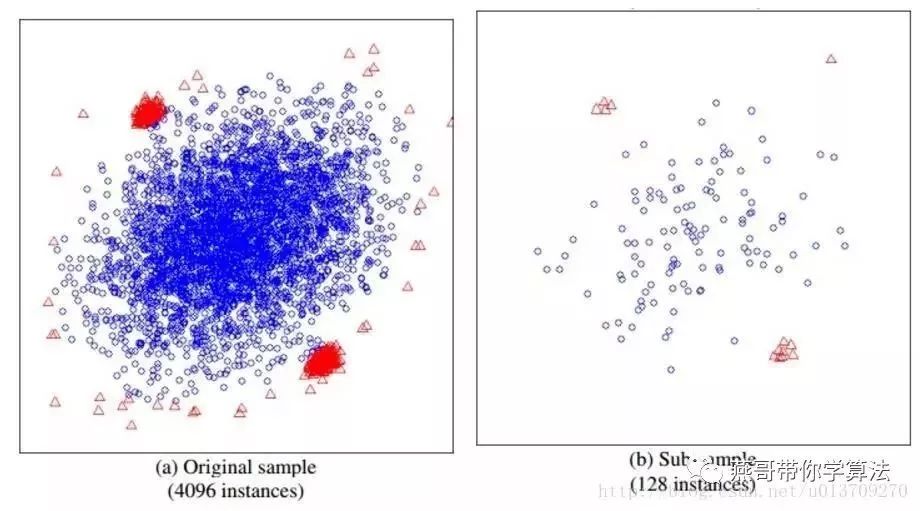
The left side is the raw data, the right side is the sampled data, the blue is the normal sample, and the red is the abnormal sample. It can be seen that before sampling, the normal sample and the abnormal sample overlap, so it is difficult to separate, but the sum of our samples, the abnormal sample and the normal sample can be clearly separated.
In addition to limiting the sampling size, we also need to set the maximum height of each iTree to l=ceilng(log2Ψ). This is because the abnormal data records are less and the path length is lower, and we only need to record the normal. It is distinguished from the exception record, so it is only necessary to care about the part below the average height, so the algorithm is more efficient, but after this adjustment, you can see that the calculation h(x) needs a little improvement, first look at iForest Fake code:

After IForest is constructed, when predicting the test, you need to synthesize the results of each tree, so
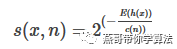
E(h(x)) represents the mean value of the height of the record x in each tree. In addition, the calculation of h(x) needs to be improved. When generating the leaf node, the algorithm records the number of records contained in the leaf node. In this case, use this quantity. Estimate the average height, h (x) is calculated as follows:

Processing of high dimensional data
When dealing with high-dimensional data, the algorithm can be improved. After sampling, not all attributes are used. Instead, the kurtosis coefficient Kurtosis is used to select some valuable attributes, and then the iTree is constructed. More like, randomly select records, and then randomly select attributes.
Use only normal samples
This algorithm is essentially an unsupervised learning, does not require the class of data, sometimes the amount of abnormal data is too small, as little as we are willing to take these abnormal samples for testing, can not be trained, the paper mentioned that only normal samples are used. Building IForest is also possible, the effect is reduced, but it is also good, and can be improved by appropriately adjusting the sample size.
to sum up
iForest has linear time complexity. Because it is the ensemble method, it can be used on data sets containing large amounts of data. Usually the more trees there are, the more stable the algorithm is. Since each tree is generated independently of each other, it can be deployed on a large-scale distributed system to speed up operations.
iForest does not apply to particularly high dimensional data. Since each dimension of the data is randomly selected one dimension, a large amount of dimension information is still not used after the tree is built, resulting in a decrease in algorithm reliability. High-dimensional space may also have a large number of noise dimensions or irrelevant attributes, which affect the construction of the tree. For this type of data, subspace anomaly detection is recommended. In addition, the cutting plane defaults to axis-parallel, and it can also randomly generate cutting planes of various angles. See “On Detecting Clustered Anomalies Using SCiForest†for details.
iForest is only sensitive to Global Anomaly, that is, global sparse point sensitive, not good at dealing with local relative sparse points (Local Anomaly). There are currently improved methods published in PAKDD, see "Improving iForest with Relative Mass".
iForest has promoted the development of Mass Estimation theory and has achieved remarkable results in both classification clustering and anomaly detection. It has been published in leading data mining conferences and journals (such as SIGKDD, ICDM, ECML).
note
At present, Yan Ge has not found a Java open source library to implement the algorithm. Currently, only the Python machine learning library scikit-learn version 0.18 implements this algorithm. Most of my projects are implemented in Java, so I need to implement the algorithm myself. The source code of the algorithm has been implemented and open sourced on my GitHub. The reader can download the source code and open the project directly with the IDEA integrated development environment, and run the test program to see the detection effect of the algorithm.Feature:
1.Material:The parts the wearer touches are not made of materials that can cause skin irritation
2.Structure:Smooth surface, no burr, no acute Angle and other defects that may cause eye and face discomfort.
It has good air permeability.
Adjustable parts and structural parts are easy to adjust and replace.
3.Package:The products are properly packaged and are accompanied by product certificates and instructions
4.fixing band : The minimum width of the headband in contact with the wearer is 11.5mm. The headband is adjustable, soft and durable
5.The appearance quality of the lens: the surface of the lens is smooth and free from scratches, ripples, bubbles, impurities, and other obvious defects that may impair vision
6.Diopter: 0.04D
7.The difference between the prism degrees of the left and right eye lenses: 0.12
8.Visible light transmission ratio: colorless transparent lens 89.35
9.Impact resistance: qualified
10.Protection performance of chemical fog drops: there is no color spot on the test paper within the center of the lens
11.Irritant gas protection performance: there is no color spot on the test paper within the center of the lens
Surgery Goggles,Eye Safety Goggles,Best Safety Goggles,Eye Goggles Protection
Guangzhou HangDeng Tech Co. Ltd , https://www.hangdengtech.com